Image Super Resolution using Efficient Cascade Dense Network (ECDN)
Efficient Cascading Dense Network
Tao Lu, Siyuan Xu, Tianyue Li.
EECS 442 course project, WN22. full report
Works on: amhyuk Ahn, Byungkon Kang, and Kyung-Ah Sohn. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European conference on computer vision (ECCV), pages 252–268, 2018.
Abstract
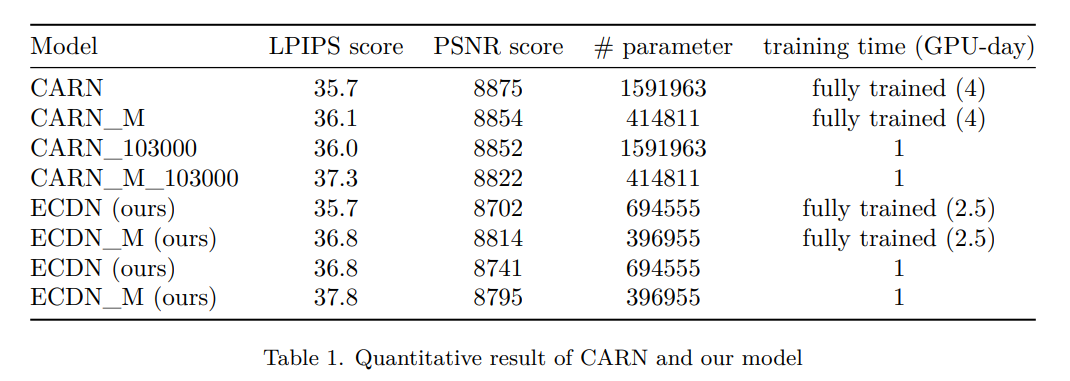
We build our Efficient Cascading Dense Network (ECDN) mainly on CARN. We choose this method because compared with other CNN for SR task, CARN achieved a more ideal balance between the training speed and accuracy. But still, CARN is not so effective. It requires more than 4 GPU-days to reach a good performance. Also, their parameter size is too large and can be reduced while preserving the performance to the large extent. Our ECDN, as well as its slimmer version, ECDN_M, achieves its performance with almost half of the original parameters.
Requirements
- Python 3
- PyTorch (0.4.0), torchvision
- Numpy, Scipy
- Pillow, Scikit-image
- h5py
- importlib
Dataset
We use DIV2K dataset for training and Set5, Set14, B100 and Urban100 dataset for the benchmark test. Here are the following steps to prepare datasets.
- Download DIV2K and unzip on
datasetdirectory as below:dataset └── DIV2K ├── DIV2K_train_HR ├── DIV2K_train_LR_bicubic ├── DIV2K_valid_HR └── DIV2K_valid_LR_bicubic - To accelerate training, we first convert training images to h5 format as follow (h5py module has to be installed).
$ cd datasets && python div2h5.py
Test Pretrained Models
We provide the pretrained models in checkpoint directory. To test CARN on benchmark dataset:
$ python carn/sample.py --model carn \
--test_data_dir dataset/<dataset> \
--scale [2|3|4] \
--ckpt_path ./checkpoint/<path>.pth \
--sample_dir <sample_dir>
and for CARN-M,
$ python carn/sample.py --model carn_m \
--test_data_dir dataset/<dataset> \
--scale [2|3|4] \
--ckpt_path ./checkpoint/<path>.pth \
--sample_dir <sample_dir> \
--group 4
Training Models
Here are our settings to train ECDN and ECDN-M. Note: We use two GPU to utilize large batch size, but if OOM error arise, please reduce batch size.
# For ECDN
$ python carn/train.py --patch_size 64 \
--batch_size 64 \
--max_steps 600000 \
--decay 400000 \
--model ecdn \
--ckpt_name ecdn \
--ckpt_dir checkpoint/ecdn \
--scale 0 \
--num_gpu 2 \
--group 4
# For ECDN-M
$ python carn/train.py --patch_size 64 \
--batch_size 64 \
--max_steps 600000 \
--decay 400000 \
--model ecdn_m \
--ckpt_name ecdn_m \
--ckpt_dir checkpoint/ecdn_m \
--scale 0 \
--group 4 \
--num_gpu 2 \
--loss_fn SmoothL1
In the --scale argument, [2, 3, 4] is for single-scale training and 0 for multi-scale learning. --group represents group size of group convolution. The differences from previous version are: 1) we increase batch size and patch size to 64 and 64. 2) Instead of using reduce_upsample argument which replace 3x3 conv of the upsample block to 1x1, we use group convolution as same way to the efficient residual block.
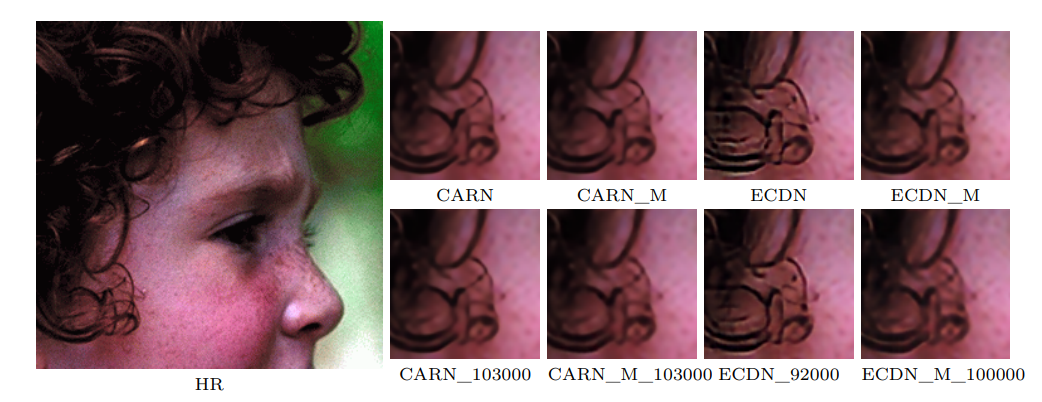
Results